Ctl.Data
Ctl.Data provides parsers for CSV (including its variants like tab-delimited pipe-delimited, etc.), fixed-width, and XLSX files (through EPPlus).
As much as we prefer high-tech solutions like web services, technologies like CSV are one of the simplest formats to get started with and are deeply embedded in many industries.
Ctl.Data was designed to deal with real-world data files: ones which might be compiled by hand in Excel, or by inconsistent code. Beyond simply reading/writing these formats, it provides full diagnostics in the form of line and column numbers, serialization, and validation through .NET's standard facilities.
Robustness takes first priority, with a number of unit tests providing wide code coverage. A close second is performance. Hand-written parsers give wicked fast reading, and are I/O agnostic to provide both blocking and fully async implementations, fully native without just throwing stuff on a task pool. Serialization and validation skip slow reflection and use code generation to ensure these conveniences don't slow things down.
Source code at GitHub
Binaries on NuGet via Ctl.Data Ctl.Data.Excel
Getting started
The simplest way to read data is via the Formats utility class:
using Ctl.Data;
using System;
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations;
class MyPoco
{
public int Foo { get; set; }
public string Bar { get; set; }
public DateTime Baz { get; set; }
public static IEnumerable<MyPoco> FromFile(string filePath)
{
return Formats.Csv.ReadObjects<MyPoco>(filePath);
}
}
Ctl.Data provides POCO serialization for either properties or fields. When working with a headered format, columns can be in any order. Serialization and validation is controlled by the same data annotations used by ASP.NET MVC and Entity Framework in addition to some new ones:
class MyPoco
{
public int Foo { get; set; }
[Required]
public string Bar { get; set; }
[DataFormat("yyyy-MM-dd")]
public DateTime Baz { get; set; }
public static IEnumerable<MyPoco> FromFile(string filePath)
{
return Formats.Csv.ReadObjects<MyPoco>(filePath, validate: true);
}
}
Any errors in parsing or subsequent validation will result in one of ParseException,
SerializationException, or ValidationException being thrown:
class ParseException : Exception
{
public long LineNumber { get; }
public long ColumnNumber { get; }
}
class SerializationException : ParseException
{
public string MemberName { get; }
public string InvalidValue { get; }
}
class ValidationException : ParseException
{
public IEnumerable<ValidationResult> Errors { get; }
public object Object { get; }
}
Writing records is similarly simple:
void WriteRecords(TextWriter tw, IEnumerable<MyPoco> records)
{
Formats.Csv.Write(tw, records);
}
Data annotation support
| Attribute | Description |
|---|---|
Column |
Controls both the name of the column and, optionally, the ordering of columns. |
AdditionalNames |
Provides alternate names to the primary one specified with Column. |
Position |
Defines indexed positions for columns, used when reading headerless files. If specified,
overrides ordering provided by the Column attribute.
|
DataFormat |
Specifies format strings, number styles, and DateTime styles. |
Fixed |
Defines the position and length of fixed-width data. If not specified, field width must be defined through other means below for the fixed-width format to work. |
StringLength |
Defines the length of fixed-width data, as well as performing usual validation. |
MaxLength |
Defines the length of fixed-width data, as well as performing usual validation. |
NotMapped |
Prevents the member from being parsed or written. |
In addition to these annotations, validation is controlled by the POCO either implementing
IValidatableObject or having ValidationAttribute annotations present.
Advanced usage
At times, it might be valuable to not throw exceptions in the event of a validation error. Perhaps
these records would be logged and reported back to the user, while the good records would still
be processed. To accomplish this, the ObjectValue class is used.
ObjectValue gives row, line, and column numbers that a row was parsed on, as well as
any errors occurred during parsing. It does not throw exceptions unless you try to retrieve the
deserialized object when an error occurred.
Again, the Formats class is generally going to provide everything needed for this:
ObjectValue<MyPoco>[] records =
Formats.Csv.ReadObjectValues<MyPoco>(filePath, validate: true).ToArray();
// filter for good values.
IEnumerable<MyPoco> goodValues =
from record in records
where record.Exception == null
select record.Value;
// filter for deserialization errors.
var deserializationErrors =
from record in records
where record.Exception != null
from exception in record.Exception.InnerExceptions
.OfType<Ctl.Data.SerializationException>()
select new
{
RowNumber = record.RowNumber,
LineNumber = exception.LineNumber,
ColumnNumber = exception.ColumnNumber,
InvalidMember = exception.MemberName,
InvalidValue = exception.InvalidValue,
ErrorMessage = exception.InnerException.Message
};
// filter for validation errors.
var badValidationRecords =
from record in records
where record.Exception != null
from exception in record.Exception.InnerExceptions
.OfType<Ctl.Data.ValidationException>()
from validationError in exception.Errors
from memberName in validationError.MemberNames
select new
{
RowNumber = record.RowNumber,
LineNumber = exception.LineNumber,
ColumnNumber = exception.ColumnNumber,
InvalidMember = memberName,
ErrorMessage = validationError.ErrorMessage
};
Another advanced usage is for a variation of a format that the Formats class doesn't cover.
This class is intended to be a quick and easy utility class for common formats, but it can be bypassed
when needed.
One such need would be to, say, parse tab-delimited files that don't have a header row:
IEnumerable<MyPoco> FromFile(string filePath)
{
using(TextReader tr = new StreamReader(filePath))
{
var csv = new CsvReader<MyPoco>(tr, separator: '\t', readHeader: false);
foreach(ObjectValue<MyPoco> v in csv.AsEnumerable())
{
yield return v.Value;
}
}
}
Parsing raw data without POCO
Sometimes we don't know our data's format ahead of time and need to just parse raw records.
To do so, the CsvReader class is used without the generic parameter <T>:
TextReader tr = ...; RowValue[] rows = new CsvReader(tr).AsEnumerable().ToArray();
Similarly to the POCO scenarios, the returned records contain exactly where the values originated from:
class RowValue : List<ColumnValue>
{
public long RowNumber { get; set; }
}
class ColumnValue
{
public string Value { get; set; }
public long LineNumber { get; set; }
public long ColumnNumber { get; set; }
}
Asynchronous usage
Ctl.Data allows fully asynchronous workflows. To do this, it integrates with Microsoft's
Ix-Async package, which provides an
IAsyncEnumerable class along with full LINQ support.
Making use of async is as simple as calling an Async variation of the methods:
string[] bars =
await (from record in Formats.Csv.ReadObjectsAsync<MyPoco>(filePath)
where record.Foo == 123
select record.Bar).ToArray(token);
Performance comparison
To test performance between iterations, we've developed a very simple benchmark using worldcitiespop.txt from Maxmind, a 144MB CSV file.
I scoured NuGet for the most popular CSV parsers to get a good comparison. I found a large number with only a small amount of downloads that I haven't included for time reasons — if there's one that's particularly fast that you would like included, please file an issue and I'll do my best to update this.
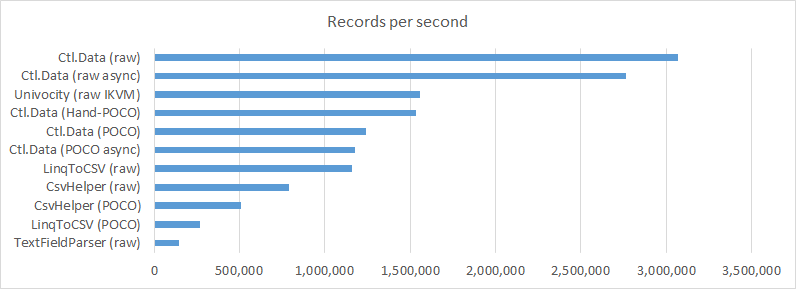
| Implementation | Records per second | Time per record (in nanoseconds) | Comparative Speed |
|---|---|---|---|
| Ctl.Data (raw) | 3,066,780 | 326 | 100% |
| Ctl.Data (raw async) | 2,763,157 | 362 | 90% |
| uniVocity (raw IKVM) | 1,554,540 | 643 | 51% |
| Ctl.Data (POCO) | 1,241,820 | 805 | 40% |
| Ctl.Data (POCO async) | 1,175,895 | 850 | 38% |
| LinqToCSV (raw) | 1,161,443 | 861 | 38% |
| CsvHelper (raw) | 791,888 | 1,261 | 26% |
| CsvHelper (POCO) | 507,525 | 1,970 | 17% |
| LinqToCSV (POCO) | 268,019 | 3,731 | 9% |
| TextFieldParser | 143,240 | 6,981 | 5% |
Benchmarking was performed by first warming up and then calling the code until it couldn't return a better time after five tries. They were all done in separate processes to ensure they don't affect each-other. File contents were read ahead of time so all results are purely in-memory. The benchmark system was an Intel 4770 with 32GB of 2400MHz DDR3 and 64-bit .NET 4.5.2 on Windows 8.1. The code is available at Github.
The results should largely speak for themselves, with Ctl.Data reading records well over twice as
fast as LinqToCSV.
Similarly, its POCO support clocked over twice as fast as
CsvHelper and even remained competitive
with LinqToCSV's raw performance. VB.NET's built-in TextFieldParser trailed well behind
the others.
For kicks I included uniVocity, the project which inspired this benchmark. It's a Java library and was run natively under .NET with the help of IKVM. IKVM is actually hurting it significantly here, as it runs with markedly better times under the actual JVM.
Beyond performance, Ctl.Data also provides the best diagnosics information with textual line and
column numbers being given for each column value. In the case of TextFieldParser, there
was only record-level line information. LinqToCSV trims whitespace from values which may or may not
be desirable, but otherwise parsed the fairly simple file identically.
Another interesting data point is Ctl.Data's async support. As no other implementation has async support at this time, this benchmark is geared to provide best-case times for synchronous (blocking) implementations by performing a single operation with no I/O at high priority and without regard for any larger system. While best for blocking, this is actually a worst-case situation for async which will show its largest improvement in a highly concurrent, I/O-bound environment. Thus, the performance differences here between sync/async are showing only the overhead that async will introduce and not the benefit. Still, it remains extremely competitive.
CSV implementation
Ctl.Data's CSV parser is designed to perfectly output and parse files compliant with RFC 4180. Not all CSV is created equal, however, so it does implement some safeguards for best-effort parsing of non-compliant files. In all cases, the parser takes the safest approach: if it's not sure, it will give an error rather than return possibly bad data.
The RFC demands any value containing quotes be escaped and quoted. In some cases, it is safe to relax this requirement while safely parsing. Consider this non-compliant file which has an obvious intent:
Name,Address Dennis "dmr" Ritchie,Foo Ln.
Related but somewhat more tricky is a value that is quoted but with incorrect escaping. This one
broke every single parser I've tested, but again in some cases, it's possible for Ctl.Data to
correctly interpret. This one can be a little dangerous to assume, so it's left as an
off-by-default configuration in the CsvReader constructor:
Name,Address "Dennis "dmr" Ritchie",Foo Ln.
Contributing and help
Development of this library takes place on Github. Bug reports, feature requests, and pull requests will be responded to as time permits.